Java EE threads v/s Node.js - which is better for concurrent data processing operations
We have started using NodeJS a lot these days typically to handle data processing applications that involve a large number of concurrent requests, each of which involve one or more I/O operations.
Why Nodejs? Why not Java? Java obviously has a much wider acceptance in the enterprise software community, while NodeJS is still to catch up. In fact this post was triggered by exactly such questions posed by the customer who belongs squarely to the enterprise software community. But before we can answer this question, we must understand what the target application is trying to do.
What does the Data Processing Application do?
The Data Processing Application is built to handle a large number of data flow processes that involve significant amount of I/O operations.
Each process involves making calls to one or more database engines using network I/O. The response of each such database call is checked for successful operation, or the received results are further processed or returned to the calling application.
The Data Processing Application needs to execute a large number of concurrent API requests, each involving multiple network I/O operations.
Java EE v/s NodeJS
The most important differences between NodeJS and Java are the concurrency and I/O models. Java uses multithreaded synchronous I/O while NodeJS uses single threaded asynchronous I/O.
| Java EE | NodeJS | |
|---|---|---|
| Concurrency Model | Multi-threaded | Single-threaded |
| I/O Model | Synchronous I/O | Asynchronous I/O |
Let us examine how these differences affect The Data Processing Application’s ability to handle a large number of concurrent requests that involve multiple I/O operations.
Concurrency Model
The following diagram illustrates the difference between the two concurrent execution models.
Java – Multi-threaded concurrency

NodeJS – Single threaded concurrency

The above diagram shows how in a multi-threaded environment, multiple requests can be concurrently executed, while in a single-thread environment multiple requests are sequentially executed. Of course, the multi-threaded environment utilizes more resources.
It may seem obvious that a multi-threaded environment will be able to handle more requests per second than the single threaded environment. This is generally true for requests that are compute intensive, which utilize the allocated resources extensively.
However, in cases where requests involve a lot of I/O such as database or web service calls, each request needs to wait for the external engine to respond to the calls made, and hence the allocated CPU and memory resources are not used during this wait time.
Synchronous v/s Asynchronous I/O
The following diagrams illustrate this scenario where requests involve I/O wait times:
Java – Synchronous I/O

NodeJS – Asynchronous I/O
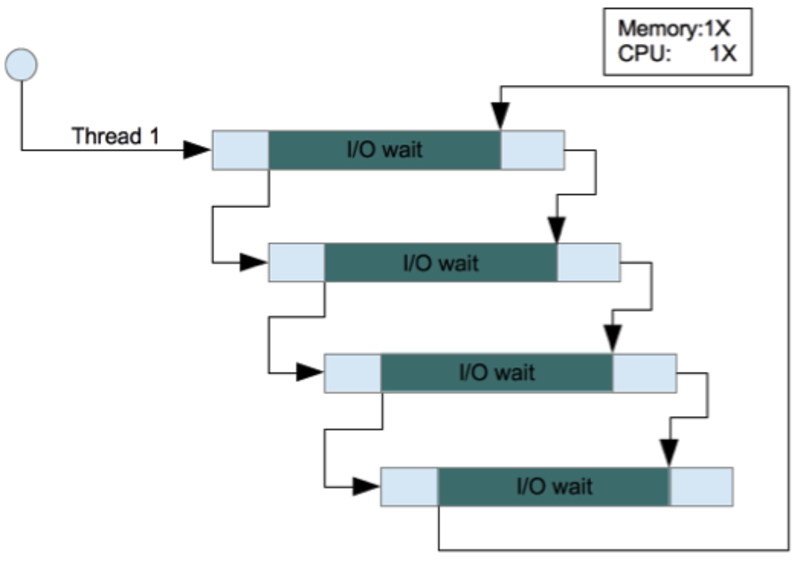
It is clear from this diagram that even though the single threaded concurrency model takes longer to execute the four requests, the amount of delay is much smaller than in the previous diagrams where there was no I/O wait time.
But what is more interesting is that the consumption of resources is still significantly smaller than in the multithreaded model. Hence to handle the same 4 requests, the Java EE multithreaded sunchronous I/O model would require significantly higher CPU and memory resources.
Hence in data processing applications where the server has to handle a large number of simultaneous requests, each of which involves I/O wait times, the single thread asynchronous I/O model of NodeJS provides a significant advantage over the multithreaded synchronous I/O model of Java EE.
Scaling out to multiple CPUs
What we saw so far holds true for a single CPU. However most servers today have multiple CPU cores. Hence it is also important to ensure that we utilize all the cores efficiently. The Node Cluster module helps in creating and managing multiple worker processes that can share the same ports and can communicate with the parent via IPC and pass server handles back and forth.
Node Cluster however only works on a single server. To scale up a nodejs application in a cluster of multiple servers, we run instances of NodeJS on each server and coordinate execution between them using a network capable IPC with 0MQ (zeroMQ) or Socket.IO. This not only allows the Data Processing Engine to use all available CPU cores on a single server, it provides a consistent mechanism to scale out the load across multiple servers.
As a result, the Data Processing Engine can be scaled out into a cluster so as to handle an increasingly larger load of data processing requests.
Conclusion
Combining the asynchronous I/O model of NodeJS with inter process communication in a cluster of processes provides a very high concurrent processing capacity to data processing applications that can be scaled out into a cluster of multiple servers.